




Discovering themes and patterns from social data mining through social media content can be a very exciting endeavor. Sometimes the questi...
Discovering themes and patterns from social data mining through social media content can be a very exciting endeavor. Sometimes the questions to be answered are too complex to be looked at in real time, or they need to establish a relationship between two or more entities, or the analysis involves multiple different phases. We call this a deep analysis. In this chapter, we delve into some use cases that require a more complex type of process or analysis, and we explore what we can uncover with a more sophisticated method analysis.
■ Identifying leads
■ Qualifying/classifying leads
■ Suggested action
 The next step was to use an IBM software package called IBM Social Media Analytics (SMA) to develop a model to perform social media data mining analysis of all the content being pulled in through the data identification phase. The sales team and social analysis team worked together iteratively to settle on the keywords that were to be used for the topic areas that we were going to focus on. During the first couple of iterations of the model-building phase, the teams realized that the list of keywords was really missing the mark. A separate effort was taken to identify the appropriate keywords for this project. While this was going on, the teams also developed a model that took in the content being provided by the initial keywords filter and classified into a broad category called “Leads.” These are considered potential sales or service opportunities based on the model. The goal was to share this with the sales and sales support teams for further steps of lead qualification and followthrough.
The next step was to use an IBM software package called IBM Social Media Analytics (SMA) to develop a model to perform social media data mining analysis of all the content being pulled in through the data identification phase. The sales team and social analysis team worked together iteratively to settle on the keywords that were to be used for the topic areas that we were going to focus on. During the first couple of iterations of the model-building phase, the teams realized that the list of keywords was really missing the mark. A separate effort was taken to identify the appropriate keywords for this project. While this was going on, the teams also developed a model that took in the content being provided by the initial keywords filter and classified into a broad category called “Leads.” These are considered potential sales or service opportunities based on the model. The goal was to share this with the sales and sales support teams for further steps of lead qualification and followthrough.
At the end of this phase, the teams had a strong list of keywords covering the following areas:
■ List of selected accounts—These are the names and aliases of the accounts that the account teams selected for this pilot project.
■ List of industries—This is a validated list of industries that cover the accounts we are interested in doing the listening for, such as Retail, Banking, and Education.
■ Subject categories—These are the specific areas of business solutions that we are interested in targeting such as Finance, Operations, Information Technology, and Security.
Figure 10.2 illustrates the process steps utilized in this phase.

One challenge encountered immediately was that there were too many potential leads but the actual number of leads to be pursued was very small. The busy salesforce was spending too much time reading through a large amount of social media updated in an attempt to identify which ones required action. In essence, the team had to wade through a number of results to find the most valuable items—sort of like looking for a needle in a pile of needles. One of the major problems was that of duplication; let us illustrate this with an example.
Suppose that the CIO of a bank gives an interview in a trade journal. In this interview, the CIO specifies that his company is about to revamp the technology infrastructure for supporting mobile access. This sounds like a clear opportunity that is worth exploring. The Social Listening Model that we had developed was designed to capture such cases and flag the story for further review and analysis by the sales team. However, what happened in this particular case (and in many other cases like these) is that the article was widely referenced in a variety of other journals, news sources, and social media venues. So, instead of having one lead about this opportunity, our system flagged over 100 references.
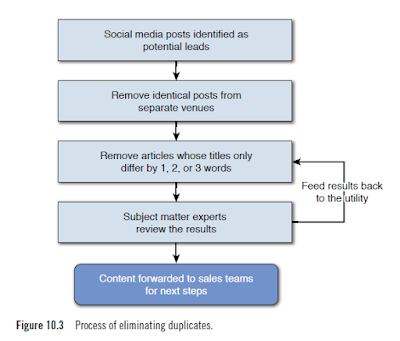
The team wrote a utility program to take the raw leads as input and weed out the duplicates. Team members first filtered out articles that had identical titles that brought the number of posts on this topic down to 70. What they noticed was that the same article would appear under a slightly different title. The team broadened the definition of duplicates to include those articles whose title differed in only one, two, or three words. This process also involved active collaboration between the analyst and business teams to ensure that we were filtering enough but not too much! This phase is typical in social media analysis projects. Even though the software makes a lot of advances in facilitating analysis of text, in certain phases manual intervention is critical to the success of the program. In our experience, this filtering/cleanup is highly specific to each deep analysis project and could require a lot of investment in terms of people time. For the sake of this discussion, we have highlighted this simple example of deduplication . This process is illustrated in Figure 10.3.
 The team would look at these leads and determine which leads to follow up on. After several months of using this approach, the team developed some logic and informal business rules for determining which leads have high potential. As of this writing, the team is looking at further automating these basic “rules of thumb.”
The team would look at these leads and determine which leads to follow up on. After several months of using this approach, the team developed some logic and informal business rules for determining which leads have high potential. As of this writing, the team is looking at further automating these basic “rules of thumb.”
The main suggested action in each of these potential leads was to follow through in an attempt to determine if we can nurture the lead into a sale. This follow-through can take on several different forms.
In this first example, let’s assume a user expresses an interest in a specific IBM product or service via Twitter. One suggestion is to respond back to the tweet with pointers to a specific white paper or customer testimonial providing more details about the product or service that the user showed an interest in. However, we can also perform some additional research on the Twitter handle to understand what sort of profile information we can gather about the user from the Twitter site. If, for example, we learn that this user is from the San Francisco Bay Area, we could send a personal invitation to an IBM event happening in the Bay Area of California, or wherever the user may be from. The point is, we can begin to establish an interest in providing more information and continuing the dialogue, which could perhaps lead to additional sales.
In another type of lead, we could uncover that a company has announced plans to investigate other markets or expand its product/service lines. We may have learned this through a news item or through a comment posted by the someone placed high in the company (such as the CIO) in social media channels or a blog. We could take this information and pass the lead on to the appropriate sales team in that region or city to explore potential sales opportunities further, perhaps getting the jump on some of our competitors.
In another example, we could stumble upon a person who shows interest in learning about some new technology—say, cognitive computing facilities being showcased by the IBM Watson division in the health-care industry. We may have learned this from a comment posted on a blog by an IBM subject matter expert. In this case, we would want to create a follow-up by posting a schedule of training events or conferences on the topic of cognitive computing given there seemed to be heightened interest. The hope is that when the person actually enrolls for a session, we can learn more about her specific situation to see if there are any potential sales leads to be explored.
Finally, let’s look at a specific example that we encountered on this project. In the preceding section on qualifying leads, we gave an example of a bank. In this particular instance, the CIO of the bank had announced that it was in the process of revamping its entire mobile platform and was looking for solutions in the area of fraud prevention. When this lead was discovered, IBM had recently acquired a company specializing in fraud detection in financial institutions. A number of steps were taken to follow up. First, an invitation was sent to this company for a conference where IBM was showcasing these services. Second, a specific meeting was arranged between the management team of this bank and the appropriate IBM services team, along with the subject matter expert in fraud prevention. As a result of these two simple follow-ups, which originated from a discovery made in social media, our IBM sales teams were able to close on a deal with the bank and our new fraud detection acquisition.
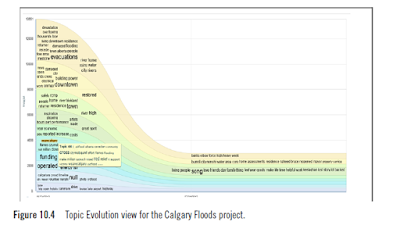
Evolving Topics is a unique algorithm that will analyze social media content to discover threads of conversation emerging in social media. This is different than a general word cloud where the focus is on overall re-occurrence in social media. When you are going to analyze social media content, you specify the time frame you want to assess evolving topics. For example, discover topics that are emerging in social media over the last 30 days. This feature will help analysts identify topics that they may not have known to include in the model. In 2013, for example, there was a massive disruption of activities due to floods. A social media analytics model was developed for understanding the issues and relief plans. When the team prepared the model, team members used some commonsense knowledge to decide on what keywords to search for. For the keywords they selected, a large amount of social media text was pulled into the model for analysis. The Top Evolution view from the SMA Package showed a number of terms that were part of the conversations that were happening around the floods in Calgary, Alberta, Canada. The analyst team did further research on many of the new and unexpected terms and were able to enhance the model with richer and more relevant keywords such as yycflood and wearecalgary.
Figure 10.4 shows the Topic Evolution view for the Calgary Floods project.
 In our experience, this feature has served us well. For many listening projects, we do not typically get a well-thought-out list of keywords. The listening team starts out with a beginning list of keywords and then uses the Topic Evolution function iteratively to enhance the list of keywords. The typical process followed in “keywords” development using Topic Evolution is illustrated in Figure 10.5.
In our experience, this feature has served us well. For many listening projects, we do not typically get a well-thought-out list of keywords. The listening team starts out with a beginning list of keywords and then uses the Topic Evolution function iteratively to enhance the list of keywords. The typical process followed in “keywords” development using Topic Evolution is illustrated in Figure 10.5.

The Affinities measure is based on a statistical method that is known as the chi-square test of independence. This method estimates how often two dimensions should occur together if they were independent (for example, products and product features). It compares the estimate with the actual count and identifies whether the difference is statistically significant (either higher or lower than expected). For the Calgary Floods project, the final model included a two-dimensional affinity matrix (see Figure 10.6).
 The vertical dimension shows a variety of geographical regions or parts affected by the flood. The horizontal dimension shows a number of issues or problem areas. The color of the cell corresponding to each combination of the Region and Issue indicates how strong the relationship is between the two dimensions. The darker the color, the more statistically significant is the relationship. For example, the matrix shows that the issue about Donations is quite strong in the Mission region. Similarly, the issues about insurance are quite strong in the region called Elbow Park. A table such as this can be used to prioritize actions in response to the issues when cities are faced with limited resources and limited time.
The vertical dimension shows a variety of geographical regions or parts affected by the flood. The horizontal dimension shows a number of issues or problem areas. The color of the cell corresponding to each combination of the Region and Issue indicates how strong the relationship is between the two dimensions. The darker the color, the more statistically significant is the relationship. For example, the matrix shows that the issue about Donations is quite strong in the Mission region. Similarly, the issues about insurance are quite strong in the region called Elbow Park. A table such as this can be used to prioritize actions in response to the issues when cities are faced with limited resources and limited time.
Figure 10.7 shows an expanded image of the top-left portion of this affinity matrix.
 The color of the cell indicates the level of affinity. The color red indicates a high affinity, orange is indicative of a medium affinity, and yellow indicates low affinity (gray is representative of no affinity or relationship). The number in each cell shows how many times the two dimensions occur together in the given dataset.
The color of the cell indicates the level of affinity. The color red indicates a high affinity, orange is indicative of a medium affinity, and yellow indicates low affinity (gray is representative of no affinity or relationship). The number in each cell shows how many times the two dimensions occur together in the given dataset.
This example shows that there is a strong correlation between driving issues and the region BonnyBrook; this is implied by the strong red color of the cell. The same chart implies that the driving related concerns are not that relevant for the Victoria Park region. You might notice that the cell associated with downtown and clean up has a big number (435); however, based on statistical weight, the affinity between these two dimensions is considered to
be low.
Affinity analysis can be a very effective tool in understanding the relationship between different dimensions of a model built for a particular use case. It becomes a critical tool for assisting with prioritization of the follow-up actions resulting from this phase of the analysis.
Responding to Leads Identified in Social Media
Many services and products in the marketplace try to facilitate discovering leads in social media. In the following sections, we discuss an experimental project that we are working on in IBM. For the purposes of this discussion, we break it up into three phases:■ Identifying leads
■ Qualifying/classifying leads
■ Suggested action
Identifying Leads
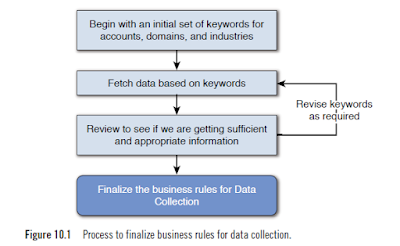
Our Social Listening team, led by Mila Gessner, began working with an account team within IBM. The goal of this exercise was to see if we could analyze conversations taking place within social network data venues, around the topics that were of interest to us or some pilot set of customers, to identify sales leads for our customer-facing marketing representatives. Team members identified 10 accounts across a variety of industries. They also identified lines of businesses within these companies to focus on. A list of key IBM competitors relevant to these accounts and the industries and lines of business were identified. Using the methods already identified in this post, the team completed the data identification phase and determined the type of data, the sources of data, and the duration of data to be included in the analysis. After several iterations, team members were able to settle on a set of keywords to use to search for content for this analysis on a daily basis. Figure 10.1 shows the process that was used in this phase.
At the end of this phase, the teams had a strong list of keywords covering the following areas:
■ List of selected accounts—These are the names and aliases of the accounts that the account teams selected for this pilot project.
■ List of industries—This is a validated list of industries that cover the accounts we are interested in doing the listening for, such as Retail, Banking, and Education.
■ Subject categories—These are the specific areas of business solutions that we are interested in targeting such as Finance, Operations, Information Technology, and Security.
Figure 10.2 illustrates the process steps utilized in this phase.

Qualifying/Classifying Leads
As discussed in the previous section, the output of the social listening team was a set of leads that could be analyzed on a daily basis. The team receiving the insights would look at the leads to identify which could be considered as real leads to be pursued.One challenge encountered immediately was that there were too many potential leads but the actual number of leads to be pursued was very small. The busy salesforce was spending too much time reading through a large amount of social media updated in an attempt to identify which ones required action. In essence, the team had to wade through a number of results to find the most valuable items—sort of like looking for a needle in a pile of needles. One of the major problems was that of duplication; let us illustrate this with an example.
Suppose that the CIO of a bank gives an interview in a trade journal. In this interview, the CIO specifies that his company is about to revamp the technology infrastructure for supporting mobile access. This sounds like a clear opportunity that is worth exploring. The Social Listening Model that we had developed was designed to capture such cases and flag the story for further review and analysis by the sales team. However, what happened in this particular case (and in many other cases like these) is that the article was widely referenced in a variety of other journals, news sources, and social media venues. So, instead of having one lead about this opportunity, our system flagged over 100 references.
The team wrote a utility program to take the raw leads as input and weed out the duplicates. Team members first filtered out articles that had identical titles that brought the number of posts on this topic down to 70. What they noticed was that the same article would appear under a slightly different title. The team broadened the definition of duplicates to include those articles whose title differed in only one, two, or three words. This process also involved active collaboration between the analyst and business teams to ensure that we were filtering enough but not too much! This phase is typical in social media analysis projects. Even though the software makes a lot of advances in facilitating analysis of text, in certain phases manual intervention is critical to the success of the program. In our experience, this filtering/cleanup is highly specific to each deep analysis project and could require a lot of investment in terms of people time. For the sake of this discussion, we have highlighted this simple example of deduplication . This process is illustrated in Figure 10.3.

Suggested Action
The analytics and sales teams worked together through many situations to identify what the next step was going to be once a lead was identified. This part of the project was very subjective, but we are able to specify some suggested actions to give you an idea of how to incorporate this in your specific project.The main suggested action in each of these potential leads was to follow through in an attempt to determine if we can nurture the lead into a sale. This follow-through can take on several different forms.
In this first example, let’s assume a user expresses an interest in a specific IBM product or service via Twitter. One suggestion is to respond back to the tweet with pointers to a specific white paper or customer testimonial providing more details about the product or service that the user showed an interest in. However, we can also perform some additional research on the Twitter handle to understand what sort of profile information we can gather about the user from the Twitter site. If, for example, we learn that this user is from the San Francisco Bay Area, we could send a personal invitation to an IBM event happening in the Bay Area of California, or wherever the user may be from. The point is, we can begin to establish an interest in providing more information and continuing the dialogue, which could perhaps lead to additional sales.
In another type of lead, we could uncover that a company has announced plans to investigate other markets or expand its product/service lines. We may have learned this through a news item or through a comment posted by the someone placed high in the company (such as the CIO) in social media channels or a blog. We could take this information and pass the lead on to the appropriate sales team in that region or city to explore potential sales opportunities further, perhaps getting the jump on some of our competitors.
In another example, we could stumble upon a person who shows interest in learning about some new technology—say, cognitive computing facilities being showcased by the IBM Watson division in the health-care industry. We may have learned this from a comment posted on a blog by an IBM subject matter expert. In this case, we would want to create a follow-up by posting a schedule of training events or conferences on the topic of cognitive computing given there seemed to be heightened interest. The hope is that when the person actually enrolls for a session, we can learn more about her specific situation to see if there are any potential sales leads to be explored.
Finally, let’s look at a specific example that we encountered on this project. In the preceding section on qualifying leads, we gave an example of a bank. In this particular instance, the CIO of the bank had announced that it was in the process of revamping its entire mobile platform and was looking for solutions in the area of fraud prevention. When this lead was discovered, IBM had recently acquired a company specializing in fraud detection in financial institutions. A number of steps were taken to follow up. First, an invitation was sent to this company for a conference where IBM was showcasing these services. Second, a specific meeting was arranged between the management team of this bank and the appropriate IBM services team, along with the subject matter expert in fraud prevention. As a result of these two simple follow-ups, which originated from a discovery made in social media, our IBM sales teams were able to close on a deal with the bank and our new fraud detection acquisition.
Support for Deep Analysis in Analytics Software
A lot of new development is happening within deep analysis in analytics software. In the following sections, we share a couple of examples of capabilities in IBM Social Media Analytics that can assist analysts in their deep analysis projects. We illustrate these capabilities in the context of another real project that we encountered.Topic Evolution
According to the SMA product documentation, Evolving Topics is defined as follows:Evolving Topics is a unique algorithm that will analyze social media content to discover threads of conversation emerging in social media. This is different than a general word cloud where the focus is on overall re-occurrence in social media. When you are going to analyze social media content, you specify the time frame you want to assess evolving topics. For example, discover topics that are emerging in social media over the last 30 days. This feature will help analysts identify topics that they may not have known to include in the model. In 2013, for example, there was a massive disruption of activities due to floods. A social media analytics model was developed for understanding the issues and relief plans. When the team prepared the model, team members used some commonsense knowledge to decide on what keywords to search for. For the keywords they selected, a large amount of social media text was pulled into the model for analysis. The Top Evolution view from the SMA Package showed a number of terms that were part of the conversations that were happening around the floods in Calgary, Alberta, Canada. The analyst team did further research on many of the new and unexpected terms and were able to enhance the model with richer and more relevant keywords such as yycflood and wearecalgary.
Figure 10.4 shows the Topic Evolution view for the Calgary Floods project.


Affinity Analysis in Reporting
In IBM Social Media Analytics, the reporting environment offers an Affinity measure for many reports. The Affinity measure analyzes how closely two dimensions (or attributes of a dimension) are related to each other. This helps analysts gain insight about possible strengths, weaknesses, opportunities, or threat areas based on the affinity between the dimensions or attributes.The Affinities measure is based on a statistical method that is known as the chi-square test of independence. This method estimates how often two dimensions should occur together if they were independent (for example, products and product features). It compares the estimate with the actual count and identifies whether the difference is statistically significant (either higher or lower than expected). For the Calgary Floods project, the final model included a two-dimensional affinity matrix (see Figure 10.6).

Figure 10.7 shows an expanded image of the top-left portion of this affinity matrix.

This example shows that there is a strong correlation between driving issues and the region BonnyBrook; this is implied by the strong red color of the cell. The same chart implies that the driving related concerns are not that relevant for the Victoria Park region. You might notice that the cell associated with downtown and clean up has a big number (435); however, based on statistical weight, the affinity between these two dimensions is considered to
be low.
Affinity analysis can be a very effective tool in understanding the relationship between different dimensions of a model built for a particular use case. It becomes a critical tool for assisting with prioritization of the follow-up actions resulting from this phase of the analysis.










COMMENTS